If you know anything about eDiscovery, you’ve probably heard about the EDRM (eDiscovery reference model). If you haven’t, it’s the industry-accepted eDiscovery process. While the breakdown seems simple enough, each stage requires complex technology designed to complete specific tasks. Compounding the fact that eDiscovery is an intricate process that requires outside tools and assistance with the massive amount of data enterprises store, eDiscovery can cost organizations a small fortune. Thankfully modern strategies and technologies can significantly cut these costs down.
eDiscovery Cost Breakdown
Collection: 4%
Processing: 36%
Review: 58%
Production: 2%
eDiscovery Process
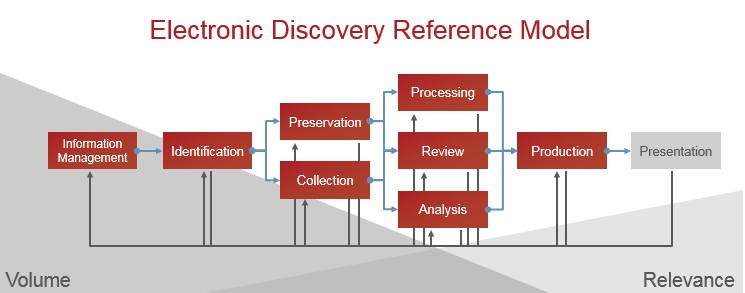
Typically, organizations break the eDiscovery process into two parts: left-hand eDiscovery, where documents are managed, found, and preserved, and right-hand eDiscovery, where documents are reviewed and presented.
While the right-hand side—especially document review—accounts for the majority of eDiscovery costs, the key to savings lies in the left-hand side. Review costs are inflated due to the massive number of false positives that cause reviewers to spend countless hours poring over irrelevant documents. However, if technology can better home in on which documents are relevant to the case, it can save organizations time, effort, and money later on.
Refining Left-Hand Discovery
The strategy for trimming document review during the left-hand side of eDiscovery wouldn’t be possible without control of your data across different sources. The first active step is identification: finding documents relevant to the case through custodians and search criteria. Scale is something to be aware of here, the largest enterprises often have sample sizes in the billions. Therefore, one massive, generic search doesn’t quite cut it. That’s why ZL performs an additional, highly specific search on the initial cull to filter out erroneous information.
From this initial pool, organizations can analyze the results to better understand what search terms generated relevant documents versus those which did not. ZL Tech uses built-in analytics, such as hit term analysis, to assess what documents have been collected, why they were collected, and how relevant they are to the case. This process allows organizations to understand the scope of a case, renegotiate search terms, and refine their case strategies. Each time reassessing their data, organizations repeat the process of finding, culling, and analyzing documents until what is left is only relevant document for legal teams to review.
ZL Tech’s eDiscovery software further reduces the number of documents for review by removing redundant findings. Notably, documents are omitted using deduplication, message threading, and tagging technology that identifies false positives and exact data copies.
Combing these strategies for refined data collection results in users of ZL Discovery Manager having a 40% reduction in documents for review and saving a total of 23% on eDiscovery costs. Interested in learning more about how ZL Discovery Manager can cut eDiscovery costs for your organization? Read the full case study.