Privacy law and AI adoption are on a collision course. Enterprises across every sector are deploying models, trained on vast pools of enterprise data, into their core workflows. At the same time, regulators around the world are expanding the rights individuals hold over their personal data, including the right to demand its deletion.
The Right to Be Forgotten is Coming for AI
Today, 144 countries have data protection and privacy regulations in place, covering 82% of the global population, up from just 10% in 2020. In 2025 alone, GDPR enforcement bodies issued more than $3 billion in fines. There are currently 20 states with comprehensive privacy laws enacted, and that number continues to grow.
These frameworks establish concrete rights for individuals, including the right to erasure in GDPR Article 17. Under this provision, individuals can request that an organization delete their personal data. For traditional databases, the process is relatively straightforward. Removing the data’s influence from a trained AI model, however, is one of the hardest open problems in machine learning.

A survey by SAS and Coleman Parkes Research found that 80% of business leaders expressed concerns about data privacy and security when evaluating generative AI. The 2026 Data Security and Compliance Risk Forecast Report predicts that “unlearning-ready” AI architectures will soon become a regulatory requirement. Organizations that cannot demonstrate personal data has been removed from their AI systems will face increasingly uncomfortable questions from regulators, auditors, and data subjects.
Why AI Doesn’t Actually Forget
The issue stems from how AI models learn. When a model trains, patterns from the data bake into billions of numerical coefficients in unpredictable ways, even to the engineers who built the system. There is no way to cleanly identify, target, and remove a specific data point’s contribution from those parameters.
A record’s influence spreads across a vast tapestry of numbers, entangled with everything else the model learned. Even if a source record is deleted when an individual submits a deletion request, the trained model still carries the fingerprint of that record.
The types of data organizations commonly need to remove from trained models include:
- Personal data erasure requests under GDPR, CCPA, and equivalent frameworks
- Training content found to be biased that skews model outputs
- Copyrighted or improperly licensed material incorporated during data collection
- Sensitive information that should never have entered the training pipeline
The only guaranteed solution is full retraining: rebuild the model from scratch using a corrected dataset that excludes the data in question. For large enterprise models trained on terabytes of unstructured data, it is prohibitively expensive in both time and compute cost. This is where “machine unlearning” research offers a more practical path.
Introducing SISA: Design for Forgetting from the Start
SISA, which stands for Sharded, Isolated, Sliced, and Aggregated, is a training framework developed to make unlearning efficient and verifiable. It is considered the leading approach to provable machine unlearning. Rather than fixing the model after training is complete, SISA restructures the training process from the beginning so that forgetting becomes a manageable, targeted operation.
Think of a traditional large language model as a complete painting. SISA breaks that painting into a jigsaw puzzle. Each piece is a small, independent model trained on its own portion of the data. When information requires removal, only the puzzle piece containing it needs retraining. The rest of the puzzle stays intact.
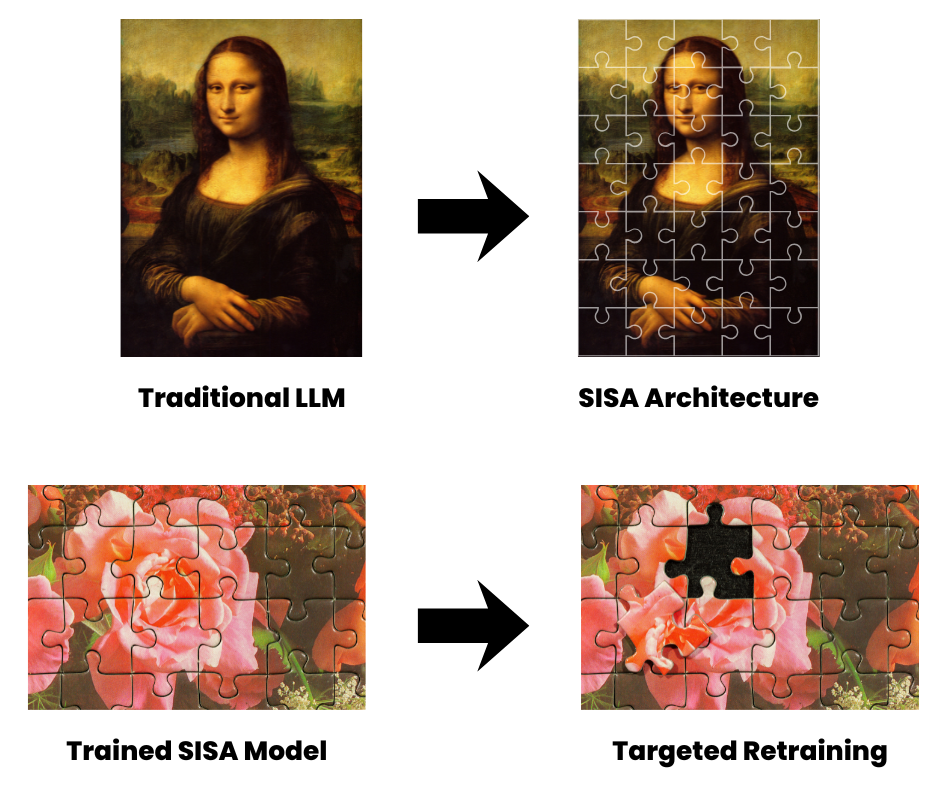
This structural change produces a dramatic reduction in computational cost. Traditional retraining scales with the full dataset, expressed as O(n). SISA brings that cost down to O(n/k + s), where k is the number of shards and s represents the average slice size. As enterprise datasets grow into the tens of billions of documents, the efficiency advantage compounds significantly.
The Four Pillars of SISA
SISA achieves unlearning-ready AI through four interlocking mechanisms:
- Sharding: The training dataset divides into non-overlapping segments called shards. Each data point lives in exactly one shard, which means its influence stays fully contained. A deletion request traces directly to a single shard, and retraining remains local.
- Isolation: Each shard trains its own independent model with no shared parameters. When one shard retrains, the others remain unchanged, preserving the work already completed across the rest of the dataset.
- Slicing: Within each shard, data loads in sequential layers called slices. The model saves a checkpoint after each slice, creating a training timeline. When a data point requires removal, the system rolls back only to the relevant checkpoint and retrains forward from there.
- Aggregation: The independent shard models combine their outputs at inference time through strategies such as averaging, weighted voting, or learned aggregation. The result behaves as a single cohesive model while preserving the modular structure underneath.
These four pillars make unlearning feasible, surgical, and auditable. SISA supports verifiable deletion, meaning organizations can demonstrate that a model’s outputs are statistically indistinguishable from a model that never encountered the removed data. Auditability matters as regulators increasingly require proof of compliance.
What SISA Demands from Your Data
The architectural elegance of SISA depends entirely on the quality and organization of the data feeding each shard. A poorly curated shard produces an undertrained model that degrades the accuracy of the entire ensemble. Getting the shards right is as much a data problem as it is a modeling problem.
This places significant demands on enterprise information governance. To build effective SISA shards and fulfill deletion obligations with precision, organizations need:
- Granular, content-based classification across all data repositories, so training data can be accurately filtered, labeled, and assigned to the appropriate shard
- Enterprise-wide search and visibility across structured and unstructured sources, ensuring the right content reaches the right shard during curation
- Precise tracking of where PII and sensitive data reside across the full data landscape, so deletion requests map cleanly to the correct shard and trigger only the retraining required
- The ability to govern and act on data across repositories without migrating it, which in-place data management provides by indexing and classifying content at its source
Enterprise data sprawls across email systems, file shares, collaboration platforms, cloud storage, and legacy repositories. Centralizing all of it via data migration is a slow, costly process. Instead, in-place management lets organizations apply classification, search, and remediation capabilities across the full data landscape from a unified platform, without disrupting where content lives.
This is the kind of governance foundation that SISA rests on. An organization lacking granular visibility into its unstructured data cannot build well-curated shards. Without the ability to locate sensitive data across its repositories, an organization cannot fulfill deletion requests with the precision that privacy frameworks require.
The Path Forward
Privacy regulation is accelerating. The right to erasure already applies to personal data wherever it lives, including inside trained models, and organizations that cannot demonstrate deletion from AI systems face significant exposure.
SISA offers a path forward. By building the capacity for forgetting into the architecture, organizations can meet deletion obligations without dismantling their AI investments. However, the “puzzle” only holds together if each piece contains the right information. That requires a governance foundation that can keep pace with the evolving demands of responsible AI adoption.